# Evaluation
We propose an homogeneous evaluation of the submitted solutions to predict the load flow in a power grid using the LIPS (Learning Industrial Physical Systems Benchmark suite) platform. The evaluation is performed through 3 categories that cover several aspects of augmented physical simulations namely:
- ML-related: standard ML metrics (e.g. MAE, MAPE, etc.) and speed-up with respect to the reference solution computational time;
- Physical compliance: respect of underlying physical laws (e.g. local and global energy conservation);
- Application-based context: out-of-distribution (OOD) generalization to extrapolate over minimal variations of the problem depending on the application.
In the ideal case, one would expect a solution to perform equally well in all categories but there is no guarantee of that. In particular, even though a solution may perform well in standard machine-learning related evaluation, it is required to assess whether the solution also properly respects the underlying physics.
# Criteria
For each above mentioned category, specific criteria related to the power grid load flow prediction task are defined:
# ML criteria
It should be noted the following metrics are used to evalute the accuracy for the various output variabels:
- MAPE90: the MAPE criteria computed on %10 highest quantile of the distribution (used for currents and powers);
- MAE: mean absolute error (used for voltages).
# Physics compliance criteria
Various metrics are provided to examine the physics compliance of proposed solutions:
- Current Positivity: Proportion of negative current
- Voltage Positivity: Proportion of negative voltages
- Losses Positivity: Proportion of negative energy losses
- Disconnected lines: Proportion of non-null
values for disconnected power lines - Energy Loss: energy losses range consistency
- Global Conservation: Mean energy losses residual MAPE(
) - Local Conservation: Mean active power residual at nodes MAPE(
) - Joule Law: MAPE($\sum_{\ell=1}^L (\hat{p}^\ell_{ex} + \hat{p}^\ell_{or}) - R \times \frac{\sum_{\ell=1}^L (\hat{a}^\ell_{ex} + \hat{a}^\ell_{or})}{2} $)
# Practical computation of score
To evaluate properly the above mentioned evaluation criteria categories, in this competition, two test datasets are provided:
- test_dataset: representing the same distribution as the training dataset (only one disconnected power line);
- test_ood_dataset: representing a slightly different distribution from the training set (with two simultaneous disconnected power lines).
The ML-related (accuracy measures) and Physical compliance criteria are computed separately on these datasets. The speed-up is computed only on test dataset as the inference time may remains same throughout the different dataset configurations.
Hence, the global score is calculated based on a linear combination formula of the above evaluation criteria categories on these datasets:
where
We explain in the following how to calculate each of the three sub-scores.
#
This sub-score is calculated based on a linear combination of 2 categories, namely: ML-related and Physics compliance.
#
For each quantity of interest, the ML-related sub-score is calculated based on two thresholds that are calibrated to indicate if the metric evaluated on the given quantity gives unacceptable/acceptable/great result. It corresponds to a score of 0 point / 1 point / 2 points, respectively. Within the sub-cateogry, Let :
, the number of unacceptable results overall (number of red circles) , the number of acceptable results overall (number of orange circles) , the number of great results overall (number of green circles)
Let also
A perfect score is obtained if all the given quantities provide great results. Indeed, we would have
#
For Physics compliance score
#
Exactly the same procedure as above for computation of
where
#
For the speed-up criteria, we calibrate the score using the
In particular, there is no advantage in providing a solution whose speed exceeds
Note that, while only the inference time appears explicitly in the score computation, it does not mean the training time is of no concern to us. In particular, if the training time overcomes a given threshold, the proposed solution will be rejected. Thus, it would be equivalent to a null global score.
# Practical example
Using the notation introduced in the previous subsection, let us consider the following configuration:
•
•
•
•
•
•
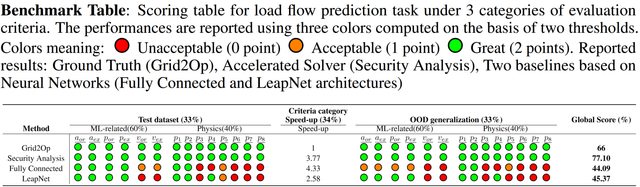
In order to illustrate even further how the score computation works, we provide in Table 2 examples for the load flow prediction task.
As it is the most straightforward to compute, we start with the global score for the solution obtained with 'Grid2Op', the physical solver used to produce the data. It is the reference physical solver, which implies that the accuracy is perfect but the speed-up is lower than the expctation. For illustration purpose, we use the speedup obtained by security analysis (explained in the begining of Notebook 5) which was
Then, by combining them, the global score is
The procedure is similar with LeapNet architecture. The associated subscores are:
Then, by combining them, the global score is